背景
我有一个摄像头视频自动化处理项目,工作流程很直接:NAS 上的摄像头视频上传到 CI 平台的 commit assets,CI 负责处理(目标检测、转码),再把结果传回 NAS 归档。
逻辑清楚,但跑起来就碰到第一个障碍——单 commit 附件有上限。
最初的设计是把输入视频和处理结果都塞进同一个 commit,结果文件一多就报错。查了下文档,CI 平台单 blob 上限 256 MiB,而我手头 77 个摄像头视频,每个平均 128MB,合计接近 10GB。单个 commit 肯定撑不住。
这不是文件大小的问题——Git LFS 解决的是大文件存储,CI 平台的 commit assets 限制是附件数量和总大小的上限。场景不同,解法也不同。
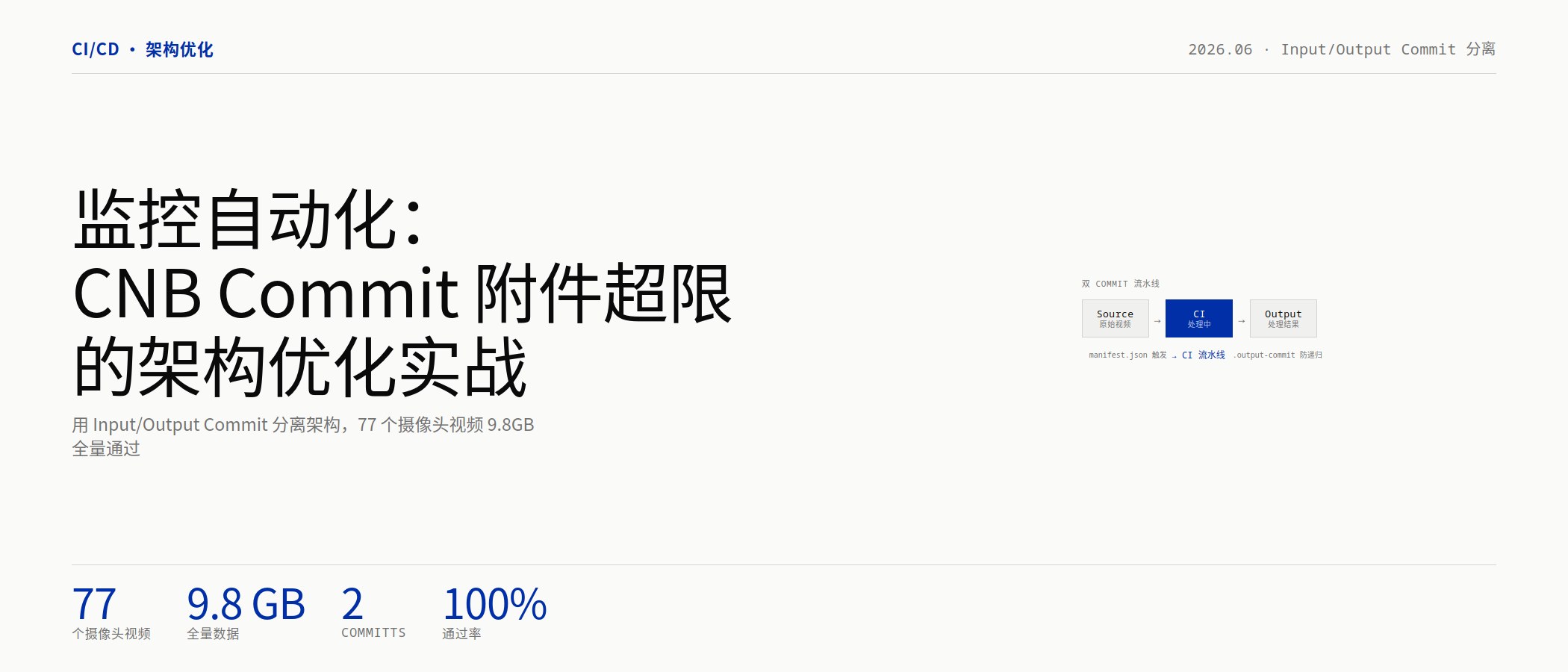
方案设计:Input/Output Commit 分离
核心思路是把输入(source)和输出(output)分配到不同的 commit 中,这样每个 commit 的附件量都远低于上限。
source commit
├── source/video_01.mp4
├── source/video_02.mp4
├── ...
└── source/manifest.json ← 触发 CI 的清单文件
↓ CI 处理
output commit
├── output/clip_01.mp4
├── output/clip_02.mp4
├── ...
├── output/summary.json
└── output/.output-commit ← 标记文件,防递归 CI

分离后每条链路职责清晰:
- source commit:只存原始视频 + 清单文件,触发 CI 处理
- output commit:只存处理结果,不触发新的 CI 循环
整个数据流分三步:
- 上传:扫描 NAS 目录,找出未处理的视频,并发上传到 source commit,创建 manifest.json 后 push 触发 CI
- 处理:CI 流水线被 manifest.json 变更触发,下载 source commit 中的视频逐个处理,结果写入 output commit
- 归档:定时任务从 output commit 拉取处理结果,传回 NAS 归档目录

双流水线设计
为了灵活应对不同场景,我配了两条流水线:
master:
push:
- name: video-filter-cpu
ifModify:
- source/manifest.json
- source/*.mp4
env:
CI_DEVICE: cpu
runner:
cpus: 2
stages:
- check-source
- download-model
- process-videos
- name: video-filter-gpu
ifModify:
- .gpu-trigger
env:
CI_DEVICE: gpu
CPU 流水线是默认路径,日常处理走它。GPU 流水线按需触发(创建 .gpu-trigger 文件即可切换),适合需要显卡加速的重型处理。
踩坑实录
解法和架构本身不复杂,真正耗时间的反而是那些看起来很小的问题。
踩坑 1:递归 CI 循环
把处理结果写回 output commit 后,push 动作又触发了一次 CI——无限循环。
根因是我最初用 git commit --allow-empty 来标记处理完成,但空 commit 没有匹配任何文件路径条件。CI 平台的默认行为是:空 commit 如果没匹配任何条件,就触发所有流水线。
解决方案是用一个标记文件:
# 用标记文件代替空 commit
echo "$COMMIT_SHA" > output/.output-commit
git add output/.output-commit
git commit -m "处理完成"
git push
.output-commit 放在 output/ 目录下,而 output/ 不在 CI 的 ifModify 条件中,所以 push 它不会触发新流水线。循环就此打断。
踩坑 2:Token Scope 不一致
本地测试时,--archive-only 模式返回 HTTP 403。查了半天,发现是本地的 Token scope 不完整——缺少 commit-assets/download 权限。
这也暴露了一个管理问题:同一套任务在不同环境(本地开发机 vs 定时任务调度器)使用不同 Token,scope 配置天然不一致,但没有人专门去对齐。
解决办法有两个:
- 重新生成包含完整 scope 的 Token,在所有环境统一使用
- 或者,把归档操作集中到权限完整的调度器上执行,不在本地调
我选了后者——归档统一走调度器,本地只做上传触发。
踩坑 3:测试环境也要小心
有几个小 bug 测试时才暴露:一个函数调用了不存在的另一个函数,一个变量在特定分支路径下未定义。这些都是跑一次就能发现的问题,但因为测试覆盖不全,到了生产才暴露。
测试策略我用了三个阶段:
1. 单文件:1 个 128MB 视频,验证整条链路通不通
2. 多文件并发:3 个 128MB 同时上传,测并发和 CI 并行处理
3. 全量运行:77 个视频 9.8GB,测极限情况
每个阶段只引入一个变量,出问题一眼就知道改了什么。
效果验证
最终生产环境全量运行的结果:
| 测试 | 文件数 | 数据量 | 结果 |
|---|---|---|---|
| 单文件 | 1 (128MB) | 128MB | 上传→处理→归档全链路通过 |
| 多文件并发 | 3 (128MB each) | 384MB | 60 秒上传,CI 3/3 成功 |
| 全量运行 | 77 (128MB each) | 9.8GB | 1520 秒,77/77 全部成功 |
source commit 只放元信息(manifest.json),0 个附件。output commit 放 4 个资产(3 个处理结果 + 1 个摘要),368 MB。每个 commit 的附件量都远远低于平台上限,空间还很大。
总结与推广
Input/Output commit 分离这个模式,看起来是针对 commit 附件上限的一个补丁,但它带来的几个收益超出预期:
- 附件解耦:输入和输出不再互相挤兑,各自的空间独立
- 递归防护:标记文件机制从根本上防止了 CI 无限循环
- 状态可追踪:一个
.ci_progress.json文件记录了 source→output 的完整映射
这套架构不只适用于视频处理。任何依赖 CI/CD 平台进行数据处理的场景都可以参考:
- 视频/图片批量处理:输入原片和输出结果分开提交
- 模型训练数据管理:训练集和模型产物不在同一个 commit 里挤
- 日志分析流水线:原始日志和分析报告分离归档
- CI 产物管理:构建输入和构建输出各自独立
关键原则就一条:不要让一个 commit 既当输入集又当输出集。分开后,每个 commit 只负责一件事,问题自然就解了。